Cadenas de texto¶
La cadena de texto (STRing) es uno de los tipos básicos de objetos de los que Python dispone. Crear una cadena de texto es muy sencillo, basta con escribir un texto entre comillas simples, dobles o triples:
>>> 'ATG'
'ATG'
>>> "ATG"
'ATG'
>>> '''ATG'''
'ATG'
Las comillas simples y dobles son completamente equivalentes mientras que las triples nos permiten introducir cadenas de texto que incluyan saltos de línea:
>>> """Hola
.... caracola"""
'Hola\ncaracola'
Otro modo de crear una cadena de texto a partir de cualquier tipo de variable es utilizar la función str(). Por ejemplo, imaginemos que queremos transformar un entero en texto:
>>> str(42)
'42'
Recordad que el tipo de objeto con el que estamos tratando es importante. Las funciones que vamos a ver a continuación se aplican a objetos del tipo cadena de texto (str), pero no funcionarían igual en enteros (int) o en números con coma (float). Para poder utilizar estas funciones con esos otros tipos primero hemos de convertirlo a una cadena de texto con la función str().
Las cadenas de texto son objetos¶
En Python las cadenas de texto son objetos. Los objetos tienen una definición informática estricta y una filosofía de programación asociada, pero lo único que necesitaremos saber para este curso es que los objetos además de los datos que contienen, incluyen funcionalidades para trabajar con ellos que definen el comportamiento de dichos objetos. Por ejemplo:
>>> 'atg'.upper()
'ATG'
Al crear la cadena de texto Python automáticamente le añade una serie de funciones para trabajar con ella. En este caso, la información sobre la cadena de texto es “atg” y varias funciones asociadas para trabajar con ella son añadidas también. Como ejemplo hemos utilizado la función upper que toma la cadena de texto original y crea, a partir de ella, una nueva cadena con las letras mayúsculas. Estas funciones de los objetos se denominan técnicamente métodos del objeto. Un método no es más que una función que actúa sobre los datos que el objeto contiene realizando alguna acción.
Aunque todavía no habíamos hablado sobre los objetos, en realidad, internamente, en Python todo son objetos. De todo esto lo único que debemos recordar es que los objetos con los que vamos a trabajar, nos ofrecerán multitud de funcionalidades extra.
Funcionalidades de las cadenas de texto¶
Las cadenas de texto incluyen multitud de métodos para derivar nuevas cadenas de texto a partir de ellas. A continuación veremos algunos ejemplos.
Podemos, por ejemplo, eliminar los espacios en blanco que encontremos al principio y al final de una cadena de texto mediante el método strip:
>>> " ATG ".strip()
'ATG'
count cuenta cuantas veces aparece una subcadena en la cadena de texto:
>>> 'TATA'.count('TA')
2
Con lower y upper podemos convertir en mayúsculas y minúsculas:
>>> 'taTA'.upper()
'TATA'
>>> 'taTA'.lower()
'tata'
replace sirve para reemplazar una cadena de texto con otra:
>>> 'ATG'.replace('T', 'U')
'AUG'
Con find podemos buscar la posición en la que aparece una subcadena dentro de otra:
>>> 'ATG'.find('T')
1
>>> 'ATG'.find('U')
-1
>>> 'ATG'.find('X')
-1
La sintaxis para obtener la longitud de la cadena de texto es algo distinta, porque aparentemente no utiliza un método sino una función:
In [63]: len('Franklin')
Out[63]: 8
En realidad, internamente, estamos usando un método, toda la aritmética y las funciones están definidas por las clases sobre las que se actúa. Existen unos métodos especiales cuyos nombres comienzan por ‘__’ que definen la aritmética. Por ejemplo, cuando utilizamos la función len internamente Python llama al método __len__ del objeto que estemos pasando a la función len. Python es pues un lenguaje orientado a objetos puro, pero utiliza algo de syntactic sugar para que nos hagamos la ilusión de que la programación es estructurada si no necesitamos hacer uso de clases.
ljust, rjust y center nos permiten obtener cadenas con una longitud determinada:
>>> 'Watson'.ljust(10)
'Watson '
>>> 'Watson'.center(10)
' Watson '
>>> 'Watson'.rjust(10)
' Watson'
Otro método muy útil es split. split nos permite dividir las cadenas de texto en una lista de subcadenas:
>>> 'nombre descripcion tipo'.split()
['nombre', 'descripcion', 'tipo']
Por defecto split divide por los espacios en blanco, pero podemos cambiar este comportamiento pasándole un parámetro:
>>> 'nombre,descripcion,tipo'.split(',')
['nombre', 'descripcion', 'tipo']
Para unir dos cadenas de texto se puede utilizar el operador suma:
>>> 'Watson' + 'Crick'
'WatsonCrick'
Si lo que queremos unir es una lista debemos utilizar el método join de la cadena que queremos utilizar para unirla:
>>> ', '.join(['Watson', 'Crick', 'Franklin'])
'Watson, Crick, Franklin'
Muchos de los métodos descritos aceptan parámetros que modifican su comportamiento. Para obtener una descripción completa del funcionamiento lo mejor es consultar un manual de referencia o utilizar la ayuda:
>>> help(str)
Además, en la ayuda, se nos informará de otras funcionalidades de las cadenas de texto que en esta breve introducción no hemos mencionado.
Índices¶
Las cadenas de texto son en realidad secuencias ordenadas de caracteres. En “ATG” el primer carácter es “A”, el segundo es “T” y el tercero es “G”. Python dispone de una sintaxis que nos permite extraer subcadenas (rebanadas) de texto muy fácilmente:
>>> texto = 'ADN y proteina'
>>> texto[0]
'A'
>>> texto[1]
'D'
En informática los índices no suelen empezar a contarse desde uno sino desde cero. Python utiliza también esa convención y por lo tanto la primera posición es la cero, no la uno.
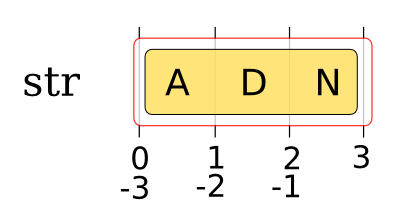
Además de poder seleccionar rebanadas de longitud uno podemos extraer subcadenas con la extensión que deseemos:
>>> texto[0:3]
'ADN'
En este caso pedimos que se extraigan todos los elementos desde el cero (incluido) al tres (no incluido). Siempre que hagamos uso de esta sintaxis deberemos tener en cuenta que el primer índice se incluye y el último no.
Para facilitar el caso común de necesitar los primeros o últimos caracteres de la cadena se permite escribir:
>>> texto[:3]
'ADN'
>>> texto[6:]
'proteina'
De este modo seleccionamos los tres primeros caracteres y desde el sexto en adelante. Para simplificar este último caso, en el que necesitamos los últimos caracteres, Python permite el uso de números negativos. Estos números los interpreta como contados desde el final. Para seleccionar los últimos 8 caracteres podemos hacer:
>>> texto [-8:]
'proteina'
Otra funcionalidad ofrecida por este sistema de índices que nos puede ser muy útil cuando tratamos con secuencias de ADN codificante son los step. Mediante un step indicamos que no queremos todos los caracteres del rango especificado sino sólo uno cada step:
>>> adn = 'AtgTgaCtt'
>>> adn[::3]
'ATC'
>>> adn[1::3]
'tgt'
>>> adn[2::3]
'gat'
Antes de acabar con los índices conviene recordar que siempre que los utilicemos sobre una cadena de texto estaremos extrayendo los caracteres y copiándolos a una nueva cadena. Se dice que las cadenas de texto son inmutables, una vez creadas no pueden ser modificadas. Si intentamos utilizar uno de estos índices para modificar una cadena de texto se generará un error:
>>> molecula = 'aTG'
>>> molecula[0] = 'A'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' object does not support item assignment
Herramientas avanzadas¶
Las cadenas de texto incluyen además un método format que nos permite crear prácticamente cualquier cadena que podamos imaginar. Este método está bien explicado en el tutorial oficial.
Python dispone de un tipo de cadena de texto llamada unicode. Este tipo de objeto permite trabajar con comodidad con texto que incluya caracteres no anglosajones como letras acentuadas. Además, en Python 3.x todas las cadenas de texto son de este tipo. Su uso es bastante similar al de las cadenas de texto que hemos visto, pero incluye métodos extra que permiten trabajar con distintas codificaciones de texto.
En Python también disponemos de toda la potencia de las expresiones regulares. Para poder utilizar esta funcionalidad hay que importar el módulo de la librería estándar llamando re.
Ejercicios¶
Crea una cadena de texto “Hola caracola” y guárdala en la variable texto.
A partir de un fichero de texto hemos leído la cadena ‘ paciente,nombre,apellido \n’. ¿Cómo podemos eliminar el retorno de carro y los espacios del principio y el final de la línea?
Guarda la cadena de texto “ACT TGA CTA” en la variable adn y cuenta cuantos nucleótidos de cada tipo tiene.
Convierte la cadena anterior a minúsculas y elimina los espacios.
¿Cuantos nucleótidos tiene la cadena de texto anterior?
Supongamos que quisiésemos imprimir una tabla y que deseamos imprimir el nombre de las muestras (muestra1) y la media de una medida asociada (4.2) dejando 20 espacios para el nombre y 10 para la media y separándolas con un tabulador ¿cómo lo harías?
Si tenemos la cadena “nombre tratamiento progresión”, ¿cómo la dividimos por los espacios? ¿Y si las cadenas fuesen “nombre tratamiento progresion\n” o “nombre\ttratamiento\tprogresion\n”
¿Podríamos volver a unir la cadena anterior separándola por comas?
En la secuencia “ATG CTA TGA” ¿cómo obtenemos los tres primeros nucleótidos? ¿Los tres últimos? ¿El primero de cada codón? ¿El segundo de cada codón?
Tenemos dos variables: longitud_hoja = 4.2 y origen = “amazonas”. ¿Cómo obtenemos una nueva cadena de texto que incluya ambas separadas por un espacio (amazonas 4.2)?
Disponemos de las variables str: longitud1 = ‘2.5’ y longitud2 = 4.7, ¿cómo podemos sumarlas?
Soluciones¶
Crea una cadena de texto “Hola caracola” y guárdala en la variable texto.
>>> texto = 'Hola mundo'
>>> print texto
Hola mundo
A partir de un fichero de texto hemos leído la cadena ‘ paciente,nombre,apellido \n’. ¿Cómo podemos eliminar el retorno de carro y los espacios del principio y el final de la línea?
>>> linea = ' paciente,nombre,apellido \n'
>>> linea.strip()
'paciente,nombre,apellido'
Guarda la cadena de texto “ACT TGA CTA” en la variable adn y cuenta cuantos nucleótidos de cada tipo tiene.
>>> adn = "ACT TGA CTA"
>>> adn.count('A')
3
>>> adn.count('T')
3
>>> adn.count('C')
2
>>> adn.count('G')
1
Convierte la cadena anterior a minúsculas y elimina los espacios.
>>> adn = adn.lower()
'act tga cta'
>>> adn.replace(' ', '')
'ACTTGACTA'
También podríamos hacerlo en un solo paso:
>>> adn.lower().replace(' ', '')
'acttgacta'
Si lo deseamos podríamos guardar el resultado en una nueva variable:
>>> adn_limpio = adn.lower().replace(' ', '')
>>> print adn_limpio
acttgacta
¿Cuantos nucleótidos tiene la cadena de texto anterior?
>>> len(adn_limpio)
9
Supongamos que quisiésemos imprimir una tabla y que deseamos imprimir el nombre de las muestras (muestra1) y la media de una medida asociada (4.2) dejando 20 espacios para el nombre y 10 para la media y separándolas con un tabulador ¿cómo lo harías?
>>> print 'muestra1'.center(20) + "\t" + str(4.2).center(10)
muestra1 4.2
Si tenemos la cadena “nombre tratamiento progresión”, ¿cómo la dividimos por los espacios?
>>> "nombre tratamiento progresión".split()
['nombre', 'tratamiento', 'progresi\xc3\xb3n']
¿Y si las cadenas fuesen “nombre tratamiento progresion\n” o “nombre\ttratamiento\tprogresion\n”
>>> linea.strip().split()
['nombre', 'tratamiento', 'progresion']
¿Podríamos volver a unir la cadena anterior separándola por comas?
>>> items = "nombre tratamiento progresión".split()
>>> ','.join(items)
'nombre,tratamiento,progresi\xc3\xb3n'
Lo mismo podríamos hacerlo también con el método replace():
>>> "nombre tratamiento progresión".replace(' ', ',')
'nombre,tratamiento,progresi\xc3\xb3n'
En la secuencia “ATG CTA TGA” ¿cómo obtenemos los tres primeros nucleótidos? ¿Los tres últimos? ¿El primero de cada codón? ¿El segundo de cada codón?
>>> adn = "ATG CTA TGA"
>>> adn[:3]
'ATG'
>>> adn[-3:]
'TGA'
>>> adn[::4]
'ACT'
>>> adn[1::4]
'TTG'
Tenemos dos variables: longitud_hoja = 4.2 y origen = “amazonas”. ¿Cómo obtenemos una nueva cadena de texto que incluya ambas separadas por un espacio (amazonas 4.2)?
>>> origen + ' ' + str(longitud_hoja)
'amazonas 4.2'
Disponemos de las variables str: longitud1 = ‘2.5’ y longitud2 = 4.7, ¿cómo podemos sumarlas?
>> longitud1 = '2.5'
>>> longitud2 = 4.7
>>> float(longitud1) + float(longitud2)
7.2000000000000002
