La Shell the UNIX¶
La Shell es un interprete de comandos. Es simplemente un modo alternativo de controlar un ordenador basado en una interfaz de texto. Podemos pedirle al ordenador que ejecute un programa o que nos proporcione una información mediante el ratón ciclando en distintos lugares del escritorio o podemos escribir una orden para conseguir el mismo objetivo. Por ejemplo, para pedirle al ordenador que nos de una lista de los archivos presentes en un directorio podemos abrir un navegador de archivos o podemos escribir en la shell:
$ ls folder_name
file_1.txt
file_2.txt
Ninguna de las dos formas de comunicarse con el ordenador es mejor que la otra aunque en ciertas ocasiones puede resultar más conveniente utilizar una u otra, aunque algunos individuos de luenga barba comentan que los hombres de verdad usan la línea de comandos. Las ventajas de la línea de comandos son:
Flexibilidad. Los programas gráficos suelen ser muy adecuados para realizar la tarea para la que han sido creados, pero son difíciles de adaptar para otras tareas. La línea de comandos de Unix es por el contrario muy flexible puesto que está formada por pequeñas herramientas que podemos combinar según nuestras necesidades.
Reproducibilidad. Documentar y repetir el proceso seguido para realizar un análisis con un programa gráfico es muy costoso puesto que es difícil describir la secuencia de clicks y doble clicks que hemos realizado. Por el contrario, los procesos realizados mediante la línea de comandos son muy fáciles de documentar puesto que tan sólo debemos guardar el texto que hemos introducido en la pantalla.
Fiabilidad. Los programas básicos de Unix fueron creados en los años 70 y han sido probados por innumerables usuarios por lo que se han convertido en piezas de código extraordinariamente confiables.
Necesidad. Hay aplicaciones que sólo pueden utilizarse mediante la línea de comandos.
Velocidad. Las interfaces gráficas suelen consumir muchos recursos mientras que los programas que funcionan en línea de comandos suelen ser extraordinariamente livianos y rápidos.
Para usar la línea de comandos hay que abrir una terminal. Se abrirá una terminal con un mensaje similar a:
usuario $
Este pequeño mensaje se denomina prompt y el cursor parpadeante que aparece junto al él indica que el ordenador está esperando una orden. El mensaje exacto que aparece en el prompt puede variar ligeramente, pero en Ubuntu suele ser similar a:
usuario@ordenador:~/documentos$
En el prompt de Ubuntu se nos muestra el nombre del usuario, el nombre del ordenador y el directorio en el que nos encontramos actualmente, es decir, el directorio de trabajo actual.
Cuando el prompt se muestra podemos ejecutar cualquier cosa, por ejemplo le podemos pedir que liste los ficheros mediante el comando ls (LiSt):
usuario $ ls
lista_libros.txt
rectas_cocina/
ls, como cualquier otro comando, es en realidad un programa que el ordenador ejecuta. Cuando escribimos la orden (y pulsamos enter) el programa se ejecuta. Mientras el programa está ejecutándose el prompt desaparece y no podemos ejecutar ningún otro comando. Pasado el tiempo el programa termina su ejecución y el prompt vuelve a aparecer. En el caso del comando ls el tiempo de ejecución es tan pequeño que suele ser imperceptible.
Los programas suelen tener unas entradas y unas salidas. Dependiendo del caso estas pueden ser ficheros o caracteres introducidos o impresos en la pantalla. Por ejemplo, el resultado de ls es simplemente una lista impresa de ficheros y directorios en la interfaz de comandos.
Normalmente el comportamiento de los programas puede ser modificado pasándoles parámetros. Por ejemplo, podríamos pedirle al programa ls que nos imprima una lista de ficheros más detallada escribiendo:
$ ls -l
Cada comando tiene unos parámetros y opciones distintos. La forma estándar de pedirles que nos enseñen cuales son estos parámetros suele ser utilizar las opciones ‘–help’ o ‘-h’, aunque esto puede variar en comandos no estándar.
$ ls --help
Modo de empleo: ls [OPCIÓN]... [FICHERO]...
List information about the FILEs (the current directory by default).
Sort entries alphabetically if none of -cftuvSUX nor --sort.
Otro modo de acceder a una documentación más detallada es acceder al manual del programa utilizando el comando man (MANual):
$ man ls
(para terminar pulsar "q")
man no es como ls, man es un programa interactivo, cuando ejecutamos el comando el programa se abre y el prompt desaparece. man es en realidad un visor de ficheros de texto por lo que cuando lo ejecutamos la pantalla se rellena con la ayuda del programa que hemos solicitado. Podemos ir hacia abajo o hacia arriba y podemos buscar en el contenido de la ayuda. El prompt y la posibilidad de ejecutar otro programa no volverán a aparecer hasta que no cerremos el programa interactivo. En el caso de man para cerrar el programa hay que pulsar la tecla “q”.
El sistema de ficheros¶
En un ordenador los archivos almacenados se organizan en directorios formando el sistema de ficheros. Estos directorios guardan una relación jerárquica, por ejemplo los directorios documentos y datos puede que se encuentre dentro del directorio juan. Esta relación se representa como:
juan/documentos
juan/datos
En algunos sistemas operativos no UNIX la barra se escribe al revés “\”, a pesar de que la convención siempre fue la contraria.
En Unix todos los directorios cuelgan de un único directorio raíz (root), incluso aunque haya distintos discos duros en el ordenador. El símbolo del directorio raíz es la barra “/”.
En el directorio raíz hay diversos directorios que, en la mayoría de los casos, sólo deberían interesarnos si estamos administrando el ordenador. Los usuarios normalmente sólo escriben dentro de un directorio de su propiedad localizado dentro de /home y denominado como su nombre de usuario.
$ ls /home
alicia juan
Nombres de directorios y archivos¶
En Unix los archivos pueden tener prácticamente cualquier nombre. Existe la convención de acabar los nombres con un punto y una pequeña extensión que indica el tipo de archivo. Pero esto es sólo una convención, en realidad podríamos no utilizar este tipo de nomenclatura.
Si deseamos utilizar nombres de archivos que no vayan a causar extraños comportamientos en el futuro lo mejor sería seguir unas cuantas reglas al nombrar un archivo:
Añadir una extensión para recordarnos el tipo de archivo, por ejemplo .txt para los archivos de texto.
- No utilizar en los nombres:
espacios,
caracteres no alfanuméricos,
ni caracteres no ingleses como letras acentuadas o eñes.
Por supuesto, podríamos crear un archivo denominado “$ñ 1.txt” para referirnos a un archivo de sonido, pero esto conllevaría una sería de problemas que aunque son solventables nos dificultarán el trabajo.
Además es importante recordar que en Unix las mayúsculas y las minúsculas no son lo mismo. Los ficheros “documento.txt”, “Documento.txt” y “DOCUMENTO.TXT” son tres ficheros distintos.
Otra convención utilizada en los sistema Unix es la de ocultar los archivos cuyos nombres comienzan por punto “.”. Por ejemplo el archivo “.oculto” no aparecerá normalmente cuando pedimos el listado de un directorio. Esto se utiliza normalmente para guardar archivos de configuración que no suelen ser utilizados directamente por los usuarios. Para listar todos los archivos (All), ya sean éstos ocultos o no se puede ejecutar:
$ ls -a
. .fontconfig .HyperTree .pki
.. fsm.jpg .ICEauthority .recently-used
Esta convención de ocultar los ficheros cuyo nombre comienza por un punto se mantiene también en el navegador gráfico de ficheros. En este caso podemos pedir que se muestren estos archivos en el menú Ver -> Mostrar los archivos ocultos.
Para acelerar el acceso a ciertos directorios existen algunos nombres especiales que son bastante útiles:
* ".." indica el directorio padre del directorio actual
* "." indica el directorio actual
* "~" representa el directorio del usuario
El directorio de trabajo¶
Muchos de los comandos que vamos a utilizar procesan archivos. Para referirnos a estos archivos deberíamos indicar en qué directorio se encuentran, pero existe la convención de asumir que los archivos se encuentran en el directorio de trabajo mientras no se indique lo contrario. El directorio de trabajo es el directorio en el que nos encontramos en el momento actual. Siempre que estemos en la línea de comandos estaremos situados dentro de un directorio de trabajo.
Por ejemplo, cuando abrimos un nuevo terminal el directorio de trabajo se sitúa en /home/nombre_de_usuario. Si ejecutamos el comando ls, el programa asumirá que queremos listar los archivos presentes en ese directorio y no en otro cualquiera. Existe un comando que nos informa sobre el directorio de trabajo actual, pwd (Print Working Directory):
$ pwd
/home/jose
Si deseamos podemos modificar el directorio de trabajo “moviéndonos” a otro directorio. Para lograrlo hay que utilizar el comando cd (Change Directory):
$ cd documentos
$ pwd
/home/jose/documentos
A partir de ese momento los comandos asumirán que si no se les indica lo contrario el directorio en el que deben trabajar es /home/jose/documentos.
El comando cd acepta además de nombres de directorios algunos otros parámetros:
cd .. Ir al directorio padre del actual.
cd Ir al directorio HOME del usuario.
cd - Ir al anterior directorio de trabajo
Permisos¶
Unix desde su origen ha sido un sistema multiusuario. Para conseguir que cada usuario pueda trabajar en sus archivos, pero que no pueda interferir accidental o deliberadamente con los archivos de otros usuarios se estableció desde el principio un sistema de permisos y privilegios. Por defecto un usuario tiene permiso para leer y modificar sus propios archivos y directorios, pero no los de los demás. En los sistemas Unix los ficheros pertenecen a un usuario concreto y existen unos permisos diferenciados para este usuario y para el resto. Además el usuario pertenece a un grupo de trabajo. Por ejemplo, el usuario Pepe puede pertenecer al grupo de trabajo “diagnostico”. Si Pepe crea un fichero este tendrá unos permisos diferentes para Pepe, para el resto de miembros de su grupo y para el resto de usuarios del ordenador. Podemos ver los permisos asociados a los ficheros utilizando el comando ls con la opción -l (Long):
~$ ls -l
total 7324
-rw-r--r-- 1 usuario diagnostico 1059 Oct 20 12:42 busqueda_leukemia_100.txt
-rw-r--r-- 1 usuario diagnostico 0 Oct 13 10:53 datos_1.txt
drwxr-xr-x 2 usuario diagnostico 4096 Oct 13 10:29 experimento
En este caso los dos ficheros listados pertenecen al usuario llamado usuario y al grupo diagnostico. Los permisos asignados al usuario, a los miembros del grupo y al resto de usuarios están resumidos en la primeras letras de cada línea:
drwxr-x---
La primera letra indica el tipo de fichero listado: (d) directorio, (-) fichero u otro tipo especial. Las siguientes nueve letras muestran, en grupos de tres, los permisos para el usuario, para el grupo y para el resto de usuarios del ordenador. Cada grupo de tres letras indica los permisos de lectura (Read), escritura (Write) y ejecución (eXecute). En el caso anterior el usuario tiene permiso de lectura, escritura y ejecución (rwx), el grupo tiene permiso de lectura y ejecución (r-x), es decir no puede modificar el fichero o el directorio, y el resto de usuarios no tienen ningún permiso (—).
En los ficheros normales el permiso de lectura indica si el fichero puede ser leído, el de escritura si puede ser modificado y el de ejecución si puede ser ejecutado. En el caso de los directorios el de escritura indica si podemos añadir o borrar ficheros del directorio y el de ejecución si podemos listar los contenidos del directorio.
Estos permisos pueden ser modificados con la orden chmod.
Rutas relativas y absolutas¶
Las rutas de los directorios pueden comenzar por barra o no. Una ruta que comienza por barra, como /home/jose/, es absoluta porque se refiere al directorio raíz. Significa: ves al directorio raíz, desciende primero a home y después a jose.
Si por el contrario utilizamos una ruta que no comienza por barra estamos definiendo una ruta relativa al directorio de trabajo actual. Por ejemplo “documentos/2009” implica que debemos ir al subdirectorio documentos del directorio actual y después movernos al subdirectorio 2009. Si nos encontrásemos al ejecutar la orden en el directorio /home/jose/trabajo acabaríamos en /home/jose/trabajo/documentos/2009.
Moviendo, renombrando y copiando ficheros¶
En primer lugar vamos a crear un fichero de prueba:
~$ touch data.txt
~$ ls
data.txt
El comando touch en este caso ha creado un fichero vacío.
Los ficheros se copian con el comando cp (CoPy):
~$ cp data.txt data.bak.txt
~$ ls
data.bak.txt data.txt
Se mueven y renombran con el mv (MoVe):
~$ mv data.txt experimento_1.txt
~$ ls
data.bak.txt experimento_1.txt
Para crear un nuevo directorio podemos utilizar la orden mkdir (MaKeDIRectory):
~$ mkdir exp_1
~$ ls
data.bak.txt exp_1 experimento_1.txt
mv también sirve para mover ficheros entre directorios:
~$ mv experimento_1.txt exp_1/
~$ ls
data.bak.txt exp_1
~$ ls exp_1/
experimento_1.txt
Los ficheros se eliminan con la orden rm (ReMove):
~$ rm data.bak.txt
~$ ls
exp_1
En la línea de comandos de los sistemas Unix cuando se borra un fichero se borra definitivamente, no hay papelera. Una vez ejecutado el rm no podremos recuperar el archivo.
Los comandos cp y rm no funcionarán bien con los directorios a no ser que modifiquemos el comportamiento que muestran por defecto:
~$ rm exp_1/
rm: cannot remove `exp_1/': Is a directory
~$ cp exp_1/ exp_1_bak/
cp: omitting directory `exp_1/'
Esto sucede porque para copiar o borrar un directorio hay que copiar o borrar todos sus contenidos recursivamente y esto podría alterar muchos datos con un sólo comando. Por esta razón se exige que estos dos comandos incluyan un modificador que les indique que sí deben funcionar recursivamente cuando tratan con directorios:
~$ cp -r exp_1/ exp_1_bak/
~$ ls
exp_1 exp_1_bak
~$ rm -r exp_1_bak/
~$ ls
exp_1
WildCards¶
En muchas ocasiones resulta útil tratar los ficheros de un modo conjunto. Por ejemplo, imaginemos que queremos mover todos los ficheros de texto a un directorio y la imágenes a otro. Creemos una pequeña demostración:
~$ touch exp_1a.txt
~$ touch exp_1b.txt
~$ touch exp_1b.jpg
~$ touch exp_1a.jpg
~$ ls
exp_1 exp_1a.jpg exp_1a.txt exp_1b.jpg exp_1b.txt
Podemos referirnos a todos los archivos que acaban en txt utilizando un asterisco:
~$ mv *txt exp_1
~$ ls
exp_1 exp_1a.jpg exp_1b.jpg
El asterisco sustituye a cualquier texto, por lo que al escribir *txt incluimos a cualquier fichero que tenga un nombre cualquiera, pero que termine con las letras txt. Podríamos por ejemplo referirnos a los ficheros del experimento 1a:
~$ ls *1a*
exp_1a.jpg
Esta herramienta es muy potente y útil, pero tenemos que tener cuidado con ella, sobre todo cuando la combinamos con rm. Por ejemplo la orden:
$ rm -r *
Borraría todos los ficheros y directorios, si lo hacemos perderemos todos los ficheros y directorios que cuelgan del actual directorio de trabajo, puede que esto sea lo que queramos, pero hemos de andar con cuidado.
Obteniendo información sobre el sistema de archivos¶
ls es un comando capaz de mostrarnos información extra sobre los archivos y directorios que lista. Por ejemplo podemos pedirle, usando la opción -l (Long), que nos muestre quién es el dueño del archivo y cuanto ocupa y qué permisos tiene además de otras cosas:
~$ ls
exp_1
~$ ls -l
total 4
drwxr-xr-x 2 usuario usuario 4096 Oct 13 09:48 exp_1
La información sobre la cantidad de disco ocupada la da por defecto en bytes, si la queremos en un formato más inteligible podemos utilizar la opción -h (Human):
~$ ls -lh
total 4.0K
drwxr-xr-x 2 usuario usuario 4.0K Oct 13 09:48 exp_1
Otros comandos útiles para conocer como está el sistema de archivos son df (Disk Free) y du (Disk Usage) que nos informan sobre como de llenos están los sistemas de archivos (como por ejemplo particiones del disco duro) y sobre cuando ocupan determinados ficheros o directorios.
Completado automático e historia¶
El intérprete de comandos dispone de algunas utilidades para facilitarnos su uso. Una de las más utilizadas es el completado automático. Podemos evitarnos escribir una gran parte de los comandos haciendo uso de la tecla tabulador. Si empezamos a escribir un comando y pulsamos la tecla tabulador el sistema completará el comando por nosotros. Para probarlo creemos los ficheros datos_1.txt, datos_2.txt y tesis.txt:
~$ touch datos_1.txt
~$ touch datos_2.txt
~$ touch experimento.txt
Si ahora empezamos a escribir cp e y pulsamos el tabulador dos veces, el intérprete de comandos completará el comando automáticamente:
~$ cp e
~$ cp experimento.txt
Si el intérprete encuentra varias alternativas completará el comando hasta el punto en el que no haya ambigüedad. Si deseamos que imprima una lista de todas las alternativas disponibles para continuar con el comando deberemos pulsar el tabulador dos veces.
~$ cp d
~$ cp datos_
datos_1.txt datos_2.txt
~$ cp datos_
Otra de las funcionalidades que más nos pueden ayudar es la historia. El intérprete recuerda todos los comandos que hemos introducido anteriormente. Si queremos podemos obtener una lista de todo lo que hemos ejecutado utilizando el comando history. Pero lo más socorrido es simplemente utilizar los cursores arriba y abajo para revisar los comandos anteriores. Otra forma de acceder a la historia es utilizar la combinación de teclas control y r. De este modo podemos buscar comandos antiguos sencillamente.
¿Donde están los ejecutables? $PATH¶
Cuando entramos en la shell y ejecutamos un programa la shell ha de saber dónde encontrar el ejecutable correspondiente a ese comando. Este ejecutable es un fichero con el mismo nombre que hemos escrito en la shell y que tiene el permiso de ejecución activado. Por ejemplo el ejecutable del comando cp es:
~$ ls -l /bin/cp
-rwxr-xr-x 1 root root 109648 2010-09-21 20:32 /bin/cp
En este caso el fichero /bin/cp es un ejecutable que pertenece al usuario root, pero que todo el mundo puede leer y ejecutar y que se encuentra en el directorio /bin. Dado que el comando cp es simplemente un fichero ejecutable en bin para utilizarlo deberíamos haber escrito su ruta completa:
~$ /bin/cp fichero1.txt fichero2.bak
Aunque podríamos haber ejecutado el comando de ese modo nunca lo hemos hecho. De alguna forma la shell ha sabido encontrar el comando cp en el directorio /bin a pesar de que no se lo hemos dicho.
Cuando intentamos ejecutar un comando lo que la shell hace es buscar el fichero ejecutable correspondiente en una lista de directorios que se encuentra almacenada en una variable de entorno denominada $PATH. Podemos imprimir esta lista utilizado el comando echo:
~$ echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games
En el ejemplo mostrado al escribir un comando en la shell, ésta lo buscará primero en el directorio /usr/local/sbin, después en /usr/local/bin y así sucesivamente hasta que lo encuentre en alguno de los directorios del $PATH. Si el comando no se encuentra la shell devolverá un error:
~$ hola
No se ha encontrado la orden «hola», quizás quiso decir:
La orden «cola» del paquete «git-cola» (universe)
hola: orden no encontrada
Cuando intentemos ejecutar programas creados por nosotros mismos o descargados desde algún lugar deberemos tener este detalle en cuenta. Por ejemplo, si descargamos un ejecutable llamado hola_mundo y después intentamos ejecutarlo, la shell no lo encontrará:
~$ ls
hola_mundo
~$ hola_mundo
No se ha encontrado la orden «hola», quizás quiso decir:
La orden «cola» del paquete «git-cola» (universe)
hola_mundo: orden no encontrada
La shell no lo encuentra porque el directorio de trabajo (“.”) no está incluido en el PATH. Podríamos ejecutar el comando si le indicamos a la shell la ruta en la que se encuentra el comando:
~$ /home/usuario/hola_mundo
Hola mundo!
También podríamos utilizar una ruta relativa:
~$ ./hola_mundo
Hola mundo!
Pipes¶
Un programa en línea de comandos, además de poder leer y escribir en algunos ficheros, toma unos argumentos como entrada, realiza una tarea e imprime una salida en la pantalla.
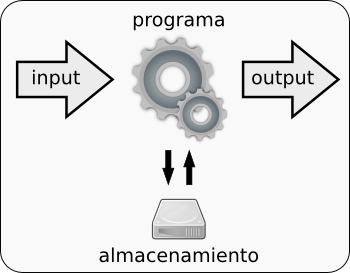
Por ejemplo, si ejecutamos el comando ls se imprime un listado en la pantalla. Este programa está creando un flujo de información, el listado, que acaba siendo imprimido en la pantalla. Este flujo de información puede ser redirigido para que no se imprima y se pierda sino que se guarde en un fichero:
~$ ls > listado.txt
~$ ls
listado.txt
Para redirigir el flujo de información desde la pantalla a un fichero no necesitamos más que utilizar el símbolo > seguido del nombre de un fichero. Si lo hacemos se creará un nuevo fichero y en él se escribirá lo que estaba destinado a la pantalla. En el caso de que el fichero de salida exista previamente será eliminado y vuelto a crear. Podríamos añadir contenidos al fichero antiguo sin borrarlo utilizando dos veces el símbolo mayor que >>.
Podemos ver los contenidos del fichero que hemos creado con el comando cat:
~$ cat listado.txt
datos_1.txt
datos_2.txt
Lo que hemos hecho se denomina técnicamente redirigir el standard output. En realidad no todo lo que acaba en la pantalla forma parte del standard output puesto que también hay otro flujo denominado standard error que los programas suelen utilizar cuando detectan un fallo. Normalmente no nos daremos cuenta de la diferencia entre ambos flujos porque ambos se imprimen en la pantalla, pero sus redirecciones son independientes.
En Unix además de redirigir los flujos de información hacia un fichero podemos unir el flujo de salida de un programa con el de entrada de otro utilizando un pipe (tubería). El símbolo para el pipe es |.
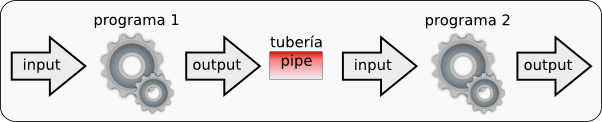
Hagamos un ejemplo con los comandos wc (Word Count) y cat. wc sirve para contar líneas, palabras y caracteres. Veamos cuantas líneas hay en el listado que habíamos creado:
~$ wc listado.txt
7 7 80 listado.txt
Podríamos hacer lo mismo en un solo paso utilizando una pipe:
~$ ls | wc
7 7 80
En este caso la salida del comando ls ha sido redirigida a la entrada del comando wc. Esta técnica es una de las grandes fortalezas de los sistemas Unix ya que permite enlazar comandos sencillos para realizar tareas complejas y vamos a utilizarla ampliamente durante el curso. Esta técnica posibilita, entre otras cosas, el procesamiento de los ficheros de texto de una forma potente y sencilla.
Ejercicios¶
¿Cuáles son los ficheros y directorios presentes en el directorio raíz?
¿Cuáles son los permisos de los directorios presentes en el directorio raíz y en nuestro directorio de usuario? ¿A quién pertenecen los ficheros y qué permisos tienen los distintos usuarios del ordenador?
¿Cuáles son todos los archivos presentes en nuestro directorio de usuario?
Crea un directorio llamado experimento.
Crea con touch los archivos datos1.txt y datos2.txt dentro del directorio experimento.
Vuelve al directorio principal de tu usuario y desde allí lista los archivos presentes en el directorio experimento.
Borra todos los archivos que contengan un 2 en el directorio experimento.
Copia el directorio experimento a un nuevo directorio llamado exp_seguridad.
Borra el directorio experimento.
Renombra el directorio exp_seguridad a experimento.
Ultimo fichero modificado en el directorio /etc.
Crear dos ficheros de texto con el editor de texto gedit y en la linea de comando crear un fichero nuevo con el contenido de los dos ficheros.
Crea un directorio en tu home y muestra los permisos que tiene.
Soluciones¶
¿Cuáles son los ficheros y directorios presentes en el directorio raíz?
$ ls /
bin dev initrd.img.old lib64 mnt root srv usr
boot etc lib lost+found opt sbin sys var
cdrom home lib32 media proc selinux tmp vmlinuz.old
¿Cuáles son los permisos de los directorios presentes en el directorio raíz y en nuestro directorio de usuario? ¿A quién pertenecen los ficheros y qué permisos tienen los distintos usuarios del ordenador?
~$ ls -l /
total 140
drwxr-xr-x 2 root root 4096 Oct 11 14:37 bin
drwxr-xr-x 4 root root 4096 Oct 6 12:26 boot
(...)
~$ ls -l ~
total 7324
-rw-r--r-- 1 usuario usuario 1059 Oct 20 12:42 busqueda_leukemia_100.txt
-rw-r--r-- 1 usuario usuario 0 Oct 13 10:53 datos_1.txt
-rw-r--r-- 1 usuario usuario 0 Oct 13 10:54 datos_2.txt
(...)
¿Cuáles son todos los archivos presentes en nuestro directorio de usuario?
~$ ls -a
. busqueda_leukemia_100.txt exp_1b.jpg .profile
.. datos_1.txt experimento.txt .viminfo
Crea un directorio llamado experimento.
~$ mkdir experimento
Crea con touch los archivos datos1.txt y datos2.txt dentro del directorio experimento.
~$ cd experimento/
~/experimento$ pwd
/home/usuario/experimento
~/experimento$ touch datos1.txt
~/experimento$ touch datos2.txt
Vuelve al directorio principal de tu usuario y desde allí lista los archivos presentes en el directorio experimento.
~/experimento$ cd ..
~$ pwd
/home/usuario
~$ ls experimento
datos1.txt datos2.txt
Borra todos los archivos que contengan un 2 en el directorio experimento.
~$ rm experimento/*2*
Copia el directorio experimento a un nuevo directorio llamado exp_seguridad.
~$ cp -r experimento exp_seguridad
Borra el directorio experimento.
~$ rm -r experimento
Renombra el directorio exp_seguridad a experimento.
~$ mv exp_seguridad/ experimento
Ultimo fichero modificado en el directorio /etc
~$ ls -ltr /etc
Crear un fichero nuevo a a partir de dos ficheros
~$ cat fichero1 fichero2 > nuevo_fichero
Crea un directorio en tu home y muestra los permisos que tiene
~$ mkdir dir
~$ ls -dl dir
Otras herramientas¶
Algunos temas que no hemos tratado en esta introducción, pero que pueden resultar de una gran utilidad son:
Control de procesos mediante los comandos ps y kill.
Sesiones persistentes mediante el comando screen (o byobu en Ubuntu).
Bibliografía¶
Hay varios cursos para iniciarse en el uso de la línea de comandos de Unix, como:
Put Yourself in Command de la Free Software Fundation (copia en
Rute User’s Tutorial and Exposition de Paul Sheer (copia en
